Neural network
The term neural network was traditionally used to refer to a network or circuit of biological neurons.[1] The modern usage of the term often refers to artificial neural networks, which are composed of artificial neurons or nodes. Thus the term has two distinct usages:
- Biological neural networks are made up of real biological neurons that are connected or functionally related in a nervous system. In the field of neuroscience, they are often identified as groups of neurons that perform a specific physiological function in laboratory analysis.
- Artificial neural networks are composed of interconnecting artificial neurons (programming constructs that mimic the properties of biological neurons). Artificial neural networks may either be used to gain an understanding of biological neural networks, or for solving artificial intelligence problems without necessarily creating a model of a real biological system. The real, biological nervous system is highly complex: artificial neural network algorithms attempt to abstract this complexity and focus on what may hypothetically matter most from an information processing point of view. Good performance (e.g. as measured by good predictive ability, low generalization error), or performance mimicking animal or human error patterns, can then be used as one source of evidence towards supporting the hypothesis that the abstraction really captured something important from the point of view of information processing in the brain. Another incentive for these abstractions is to reduce the amount of computation required to simulate artificial neural networks, so as to allow one to experiment with larger networks and train them on larger data sets.
This article focuses on the relationship between the two concepts; for detailed coverage of the two different concepts refer to the separate articles: biological neural network and artificial neural network.
Contents |
Overview
A biological neural network is composed of a group or groups of chemically connected or functionally associated neurons. A single neuron may be connected to many other neurons and the total number of neurons and connections in a network may be extensive. Connections, called synapses, are usually formed from axons to dendrites, though dendrodendritic microcircuits[2] and other connections are possible. Apart from the electrical signaling, there are other forms of signaling that arise from neurotransmitter diffusion, which have an effect on electrical signaling. As such, neural networks are extremely complex.
Artificial intelligence and cognitive modeling try to simulate some properties of biological neural networks. While similar in their techniques, the former has the aim of solving particular tasks, while the latter aims to build mathematical models of biological neural systems.
In the artificial intelligence field, artificial neural networks have been applied successfully to speech recognition, image analysis and adaptive control, in order to construct software agents (in computer and video games) or autonomous robots. Most of the currently employed artificial neural networks for artificial intelligence are based on statistical estimations, classification optimization and control theory.
The cognitive modelling field involves the physical or mathematical modeling of the behavior of neural systems; ranging from the individual neural level (e.g. modeling the spike response curves of neurons to a stimulus), through the neural cluster level (e.g. modelling the release and effects of dopamine in the basal ganglia) to the complete organism (e.g. behavioral modelling of the organism's response to stimuli). Artificial intelligence, cognitive modelling, and neural networks are information processing paradigms inspired by the way biological neural systems process data.
History of the neural network analogy
In the brain, spontaneous order appears to arise out of decentralized networks of simple units (neurons).
Neural network theory has served both to better identify how the neurons in the brain function and to provide the basis for efforts to create artificial intelligence. The preliminary theoretical base for contemporary neural networks was independently proposed by Alexander Bain[3] (1873) and William James[4] (1890). In their work, both thoughts and body activity resulted from interactions among neurons within the brain.
For Bain,[3] every activity led to the firing of a certain set of neurons. When activities were repeated, the connections between those neurons strengthened. According to his theory, this repetition was what led to the formation of memory. The general scientific community at the time was skeptical of Bain’s[3] theory because it required what appeared to be an inordinate number of neural connections within the brain. It is now apparent that the brain is exceedingly complex and that the same brain “wiring” can handle multiple problems and inputs.
James’s[4] theory was similar to Bain’s,[3] however, he suggested that memories and actions resulted from electrical currents flowing among the neurons in the brain. His model, by focusing on the flow of electrical currents, did not require individual neural connections for each memory or action.
C. S. Sherrington[5] (1898) conducted experiments to test James’s theory. He ran electrical currents down the spinal cords of rats. However, instead of the demonstrating an increase in electrical current as projected by James, Sherrington found that the electrical current strength decreased as the testing continued over time. Importantly, this work led to the discovery of the concept of habituation.
McCullouch and Pitts[6] (1943) created a computational model for neural networks based on mathematics and algorithms. They called this model threshold logic. The model paved the way for neural network research to split into two distinct approaches. One approach focused on biological processes in the brain and the other focused on the application of neural networks to artificial intelligence.
In the late 1940s psychologist Donald Hebb[7] created a hypothesis of learning based on the mechanism of neural plasticity that is now known as Hebbian learning. Hebbian learning is considered to be a 'typical' unsupervised learning rule and its later variants were early models for long term potentiation. These ideas started being applied to computational models in 1948 with Turing's B-type machines.
Farley and Clark[8] (1954) first used computational machines, then called calculators, to simulate a Hebbian network at MIT. Other neural network computational machines were created by Rochester, Holland, Habit, and Duda[9] (1956).
Rosenblatt[10] (1958) created the perceptron, an algorithm for pattern recognition based on a two-layer learning computer network using simple addition and subtraction. With mathematical notation, Rosenblatt also described circuitry not in the basic perceptron, such as the exclusive-or circuit, a circuit whose mathematical computation could not be processed until after the backpropogation algorithm was created by Werbos[11] (1975).
The perceptron is essentially a linear classifier for classifying data 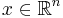 specified by parameters
specified by parameters 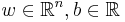 and an output function
and an output function 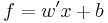 . Its parameters are adapted with an ad-hoc rule similar to stochastic steepest gradient descent. Because the inner product is a linear operator in the input space, the perceptron can only perfectly classify a set of data for which different classes are linearly separable in the input space, while it often fails completely for non-separable data. While the development of the algorithm initially generated some enthusiasm, partly because of its apparent relation to biological mechanisms, the later discovery of this inadequacy caused such models to be abandoned until the introduction of non-linear models into the field.
. Its parameters are adapted with an ad-hoc rule similar to stochastic steepest gradient descent. Because the inner product is a linear operator in the input space, the perceptron can only perfectly classify a set of data for which different classes are linearly separable in the input space, while it often fails completely for non-separable data. While the development of the algorithm initially generated some enthusiasm, partly because of its apparent relation to biological mechanisms, the later discovery of this inadequacy caused such models to be abandoned until the introduction of non-linear models into the field.
Neural network research stagnated after the publication of research of machine learning research by Minsky and Papert[12] (1969). They discovered two key issues with the computational machines that processed neural networks. The first issue was that single-layer neural networks were incapable of processing the exclusive-or circuit. The second significant issue was that computers were not sophisticated enough to effectively handle the long run time required by large neural networks. Neural network research slowed until computers achieved greater processing power. Also key in later advances was the backpropogation algorithm which effectively solved the exclusive-or problem (Werbos 1975).[11]
The cognitron (1975) designed by Kunihiko Fukushima[13] was an early multilayered neural network with a training algorithm. The actual structure of the network and the methods used to set the interconnection weights change from one neural strategy to another, each with its advantages and disadvantages. Networks can propagate information in one direction only, or they can bounce back and forth until self-activation at a node occurs and the network settles on a final state. The ability for bi-directional flow of inputs between neurons/nodes was produced with the Hopfield's network (1982), and specialization of these node layers for specific purposes was introduced through the first hybrid network.
The parallel distributed processing of the mid-1980s became popular under the name connectionism. The text by Rummelhart and McClelland[14] (1986) provided a full exposition of the use connectionism in computers to simulate neural processes.
The rediscovery of the backpropagation algorithm was probably the main reason behind the repopularisation of neural networks after the publication of "Learning Internal Representations by Error Propagation" in 1986 (Though backpropagation itself dates from 1969). The original network utilized multiple layers of weight-sum units of the type 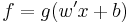 , where
, where 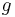 was a sigmoid function or logistic function such as used in logistic regression. Training was done by a form of stochastic gradient descent. The employment of the chain rule of differentiation in deriving the appropriate parameter updates results in an algorithm that seems to 'backpropagate errors', hence the nomenclature. However it is essentially a form of gradient descent. Determining the optimal parameters in a model of this type is not trivial, and local numerical optimization methods such as gradient descent can be sensitive to initialization because of the presence of local minima of the training criterion. In recent times, networks with the same architecture as the backpropagation network are referred to as multilayer perceptrons. This name does not impose any limitations on the type of algorithm used for learning.
was a sigmoid function or logistic function such as used in logistic regression. Training was done by a form of stochastic gradient descent. The employment of the chain rule of differentiation in deriving the appropriate parameter updates results in an algorithm that seems to 'backpropagate errors', hence the nomenclature. However it is essentially a form of gradient descent. Determining the optimal parameters in a model of this type is not trivial, and local numerical optimization methods such as gradient descent can be sensitive to initialization because of the presence of local minima of the training criterion. In recent times, networks with the same architecture as the backpropagation network are referred to as multilayer perceptrons. This name does not impose any limitations on the type of algorithm used for learning.
The backpropagation network generated much enthusiasm at the time and there was much controversy about whether such learning could be implemented in the brain or not, partly because a mechanism for reverse signaling was not obvious at the time, but most importantly because there was no plausible source for the 'teaching' or 'target' signal. However, since 2006, several unsupervised learning procedures have been proposed for neural networks with one or more layers, using so-called deep learning algorithms. These algorithms can be used to learn intermediate representations, with or without a target signal, that capture the salient features of the distribution of sensory signals arriving at each layer of the neural network.
The brain, neural networks and computers
Neural networks, as used in artificial intelligence, have traditionally been viewed as simplified models of neural processing in the brain, even though the relation between this model and brain biological architecture is debated, as little is known about how the brain actually works.
A subject of current research in theoretical neuroscience is the question surrounding the degree of complexity and the properties that individual neural elements should have to reproduce something resembling animal intelligence.
Historically, computers evolved from the von Neumann architecture, which is based on sequential processing and execution of explicit instructions. On the other hand, the origins of neural networks are based on efforts to model information processing in biological systems, which may rely largely on parallel processing as well as implicit instructions based on recognition of patterns of 'sensory' input from external sources. In other words, at its very heart a neural network is a complex statistical processor (as opposed to being tasked to sequentially process and execute).
Neural coding is concerned with how sensory and other information is represented in the brain by neurons. The main goal of studying neural coding is to characterize the relationship between the stimulus and the individual or ensemble neuronal responses and the relationship among electrical activity of the neurons in the ensemble.[16] It is thought that neurons can encode both digital and analog information.[17]
Neural networks and artificial intelligence
A neural network (NN), in the case of artificial neurons called artificial neural network (ANN) or simulated neural network (SNN), is an interconnected group of natural or artificial neurons that uses a mathematical or computational model for information processing based on a connectionistic approach to computation. In most cases an ANN is an adaptive system that changes its structure based on external or internal information that flows through the network.
In more practical terms neural networks are non-linear statistical data modeling or decision making tools. They can be used to model complex relationships between inputs and outputs or to find patterns in data.
However, the paradigm of neural networks - i.e., implicit, not explicit , learning is stressed - seems more to correspond to some kind of natural intelligence than to the traditional symbol-based Artificial Intelligence, which would stress, instead, rule-based learning.
Background
An artificial neural network involves a network of simple processing elements (artificial neurons) which can exhibit complex global behavior, determined by the connections between the processing elements and element parameters. Artificial neurons were first proposed in 1943 by Warren McCulloch, a neurophysiologist, and Walter Pitts, a logician, who first collaborated at the University of Chicago.[18]
One classical type of artificial neural network is the recurrent Hopfield net.
In a neural network model simple nodes (which can be called by a number of names, including "neurons", "neurodes", "Processing Elements" (PE) and "units"), are connected together to form a network of nodes — hence the term "neural network". While a neural network does not have to be adaptive per se, its practical use comes with algorithms designed to alter the strength (weights) of the connections in the network to produce a desired signal flow.
In modern software implementations of artificial neural networks the approach inspired by biology has more or less been abandoned for a more practical approach based on statistics and signal processing. In some of these systems, neural networks, or parts of neural networks (such as artificial neurons), are used as components in larger systems that combine both adaptive and non-adaptive elements.
The concept of a neural network appears to have first been proposed by Alan Turing in his 1948 paper "Intelligent Machinery".
Applications of natural and of artificial neural networks
The utility of artificial neural network models lies in the fact that they can be used to infer a function from observations and also to use it. Unsupervised neural networks can also be used to learn representations of the input that capture the salient characteristics of the input distribution, e.g., see the Boltzmann machine (1983), and more recently, deep learning algorithms, which can implicitly learn the distribution function of the observed data. Learning in neural networks is particularly useful in applications where the complexity of the data or task makes the design of such functions by hand impractical.
The tasks to which artificial neural networks are applied tend to fall within the following broad categories:
- Function approximation, or regression analysis, including time series prediction and modeling.
- Classification, including pattern and sequence recognition, novelty detection and sequential decision making.
- Data processing, including filtering, clustering, blind signal separation and compression.
Application areas of ANNs include system identification and control (vehicle control, process control), game-playing and decision making (backgammon, chess, racing), pattern recognition (radar systems, face identification, object recognition), sequence recognition (gesture, speech, handwritten text recognition), medical diagnosis, financial applications, data mining (or knowledge discovery in databases, "KDD"), visualization and e-mail spam filtering.
Neural networks and neuroscience
Theoretical and computational neuroscience is the field concerned with the theoretical analysis and computational modeling of biological neural systems. Since neural systems are intimately related to cognitive processes and behaviour, the field is closely related to cognitive and behavioural modeling.
The aim of the field is to create models of biological neural systems in order to understand how biological systems work. To gain this understanding, neuroscientists strive to make a link between observed biological processes (data), biologically plausible mechanisms for neural processing and learning (biological neural network models) and theory (statistical learning theory and information theory).
Types of models
Many models are used in the field, each defined at a different level of abstraction and trying to model different aspects of neural systems. They range from models of the short-term behaviour of individual neurons, through models of how the dynamics of neural circuitry arise from interactions between individual neurons, to models of how behaviour can arise from abstract neural modules that represent complete subsystems. These include models of the long-term and short-term plasticity of neural systems and its relation to learning and memory, from the individual neuron to the system level.
Current research
While initially research had been concerned mostly with the electrical characteristics of neurons, a particularly important part of the investigation in recent years has been the exploration of the role of neuromodulators such as dopamine, acetylcholine, and serotonin on behaviour and learning.
Biophysical models, such as BCM theory, have been important in understanding mechanisms for synaptic plasticity, and have had applications in both computer science and neuroscience. Research is ongoing in understanding the computational algorithms used in the brain, with some recent biological evidence for radial basis networks and neural backpropagation as mechanisms for processing data.
Computational devices have been created in CMOS for both biophysical simulation and neuromorphic computing. More recent efforts show promise for creating nanodevices[19] for very large scale principal components analyses and convolution. If successful, these efforts could usher in a new era of neural computing[20] that is a step beyond digital computing, because it depends on learning rather than programming and because it is fundamentally analog rather than digital even though the first instantiations may in fact be with CMOS digital devices.
Architecture
The basic architecture consists of three types of neuron layers: input, hidden, and output. In feed-forward networks, the signal flow is from input to output units, strictly in a feed-forward direction. The data processing can extend over multiple layers of units, but no feedback connections are present. Recurrent networks contain feedback connections. Contrary to feed-forward networks, the dynamical properties of the network are important. In some cases, the activation values of the units undergo a relaxation process such that the network will evolve to a stable state in which these activations do not change anymore.
In other applications, the changes of the activation values of the output neurons are significant, such that the dynamical behavior constitutes the output of the network. Other neural network architectures include adaptive resonance theory maps and competitive networks.
Criticism
A common criticism of neural networks, particularly in robotics, is that they require a large diversity of training for real-world operation. This is not surprising, since any learning machine needs sufficient representative examples in order to capture the underlying structure that allows it to generalize to new cases. Dean Pomerleau, in his research presented in the paper "Knowledge-based Training of Artificial Neural Networks for Autonomous Robot Driving," uses a neural network to train a robotic vehicle to drive on multiple types of roads (single lane, multi-lane, dirt, etc.). A large amount of his research is devoted to (1) extrapolating multiple training scenarios from a single training experience, and (2) preserving past training diversity so that the system does not become overtrained (if, for example, it is presented with a series of right turns – it should not learn to always turn right). These issues are common in neural networks that must decide from amongst a wide variety of responses, but can be dealt with in several ways, for example by randomly shuffling the training examples, by using a numerical optimization algorithm that does not take too large steps when changing the network connections following an example, or by grouping examples in so-called mini-batches.
A. K. Dewdney, a former Scientific American columnist, wrote in 1997, "Although neural nets do solve a few toy problems, their powers of computation are so limited that I am surprised anyone takes them seriously as a general problem-solving tool." (Dewdney, p. 82)
Arguments for Dewdney's position are that to implement large and effective software neural networks, much processing and storage resources need to be committed. While the brain has hardware tailored to the task of processing signals through a graph of neurons, simulating even a most simplified form on Von Neumann technology may compel a NN designer to fill many millions of database rows for its connections - which can consume vast amounts of computer memory and hard disk space. Furthermore, the designer of NN systems will often need to simulate the transmission of signals through many of these connections and their associated neurons - which must often be matched with incredible amounts of CPU processing power and time. While neural networks often yield effective programs, they too often do so at the cost of efficiency (they tend to consume considerable amounts of time and money).
Arguments against Dewdney's position are that neural nets have been successfully used to solve many complex and diverse tasks, ranging from autonomously flying aircraft [2] to detecting credit card fraud [3].
Technology writer Roger Bridgman commented on Dewdney's statements about neural nets:
Neural networks, for instance, are in the dock not only because they have been hyped to high heaven, (what hasn't?) but also because you could create a successful net without understanding how it worked: the bunch of numbers that captures its behaviour would in all probability be "an opaque, unreadable table...valueless as a scientific resource". In spite of his emphatic declaration that science is not technology, Dewdney seems here to pillory neural nets as bad science when most of those devising them are just trying to be good engineers. An unreadable table that a useful machine could read would still be well worth having.[21]
In response to this kind of criticism, one should note that although it is true that analyzing what has been learned by an artificial neural network is difficult, it is much easier to do so than to analyze what has been learned by a biological neural network. Furthermore, researchers involved in exploring learning algorithms for neural networks are gradually uncovering generic principles which allow a learning machine to be successful. For example, Bengio and LeCun (2007) wrote an article regarding local vs non-local learning, as well as shallow vs deep architecture [4].
Some other criticisms came from believers of hybrid models (combining neural networks and symbolic approaches). They advocate the intermix of these two approaches and believe that hybrid models can better capture the mechanisms of the human mind (Sun and Bookman 1990).
See also
References
- ^ J. J. HOPFIELD Neural networks and physical systems with emergent collective computational abilities. Proc. NatL Acad. Sci. USA Vol. 79, pp. 2554-2558, April 1982 Biophysics [1]
- ^ Arbib, p.666
- ^ a b c d Bain (1873). Mind and Body: The Theories of Their Relation. New York: D. Appleton and Company.
- ^ a b James (1890). The Principles of Psychology. New York: H. Holt and Company.
- ^ Sherrington, C.S.. "Experiments in Examination of the Peripheral Distribution of the Fibers of the Posterior Roots of Some Spinal Nerves". Proceedings of the Royal Society of London 190: 45–186.
- ^ McCullock, Warren; Walter Pitts (1943). "A Logical Calculus of Ideas Immanent in Nervous Activity". Bulletin of Mathematical Biophysics 5 (4): 115–133. doi:10.1007/BF02478259.
- ^ Hebb, Donald (1949). The Organization of Behavior. New York: Wiley.
- ^ Farley, B; W.A. Clark (1954). "Simulation of Self-Organizing Systems by Digital Computer". IRE Transactions on Information Theory 4 (4): 76–84. doi:10.1109/TIT.1954.1057468.
- ^ Rochester, N.; J.H. Holland, L.H. Habit, and W.L. Duda (1956). "Tests on a cell assembly theory of the action of the brain, using a large digital computer". IRE Transactions on Information Theory 2 (3): 80–93. doi:10.1109/TIT.1956.1056810.
- ^ Rosenblatt, F. (1958). "The Perceptron: A Probalistic Model For Information Storage And Organization In The Brain". Psychological Review 65 (6): 386–408. doi:10.1037/h0042519. PMID 13602029.
- ^ a b Werbos, P.J. (1975). Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences.
- ^ Minsky, M.; S. Papert (1969). An Introduction to Computational Geometry. MIT Press. ISBN 0262630222.
- ^ Fukushima, Kunihiko (1975). "Cognitron: A self-organizing multilayered neural network". Biological Cybernetics 20 (3–4): 121–136. doi:10.1007/BF00342633. PMID 1203338.
- ^ Rummelhart, D.E; James McClelland (1986). Parallel Distributed Processing: Explorations in the Microstructure of Cognition. Cambridge: MIT Press.
- ^ "PLoS Computational Biology Issue Image". PLoS Computational Biology 6 (8): ev06.ei08. 2010. doi:10.1371/image.pcbi.v06.i08.
- ^ Brown EN, Kass RE, Mitra PP. (2004). "Multiple neural spike train data analysis: state-of-the-art and future challenges". Nature Neuroscience 7 (5): 456–61. doi:10.1038/nn1228. PMID 15114358.
- ^ Spike arrival times: A highly efficient coding scheme for neural networks, SJ Thorpe - Parallel processing in neural systems, 1990
- ^ McCulloch, Warren; Pitts, Walter, "A Logical Calculus of Ideas Immanent in Nervous Activity", 1943, Bulletin of Mathematical Biophysics 5:115-133.
- ^ Yang, J. J.; Pickett, M. D.; Li, X. M.; Ohlberg, D. A. A.; Stewart, D. R.; Williams, R. S. Nat. Nanotechnol. 2008, 3, 429–433.
- ^ Strukov, D. B.; Snider, G. S.; Stewart, D. R.; Williams, R. S. Nature 2008, 453, 80–83.
- ^ Roger Bridgman's defence of neural networks
Further reading
- Arbib, Michael A. (Ed.) (1995). The Handbook of Brain Theory and Neural Networks.
- Alspector, U.S. Patent 4,874,963 "Neuromorphic learning networks". October 17, 1989.
- Agre, Philip E. (1997). Computation and Human Experience. Cambridge University Press. ISBN 0-521-38603-9., p. 80
- Yaneer Bar-Yam (2003). Dynamics of Complex Systems, Chapter 2. http://necsi.edu/publications/dcs/Bar-YamChap2.pdf.
- Yaneer Bar-Yam (2003). Dynamics of Complex Systems, Chapter 3. http://necsi.edu/publications/dcs/Bar-YamChap3.pdf.
- Yaneer Bar-Yam (2005). Making Things Work. http://necsi.edu/publications/mtw/. See chapter 3.
- Bertsekas, Dimitri P. (1999). Nonlinear Programming. ISBN 1886529000.
- Bertsekas, Dimitri P. & Tsitsiklis, John N. (1996). Neuro-dynamic Programming. ISBN 1886529108.
- Bhadeshia H. K. D. H. (1992). "Neural Networks in Materials Science". ISIJ International 39 (10): 966–979. doi:10.2355/isijinternational.39.966. http://www.msm.cam.ac.uk/phase-trans/abstracts/neural.review.pdf.
- Boyd, Stephen & Vandenberghe, Lieven (2004). Convex Optimization. http://www.stanford.edu/~boyd/cvxbook/.
- Dewdney, A. K. (1997). Yes, We Have No Neutrons: An Eye-Opening Tour through the Twists and Turns of Bad Science. Wiley, 192 pp. ISBN 0471108065. See chapter 5.
- Egmont-Petersen, M., de Ridder, D., Handels, H. (2002). "Image processing with neural networks - a review". Pattern Recognition 35 (10): 2279–2301. doi:10.1016/S0031-3203(01)00178-9.
- Fukushima, K. (1975). "Cognitron: A Self-Organizing Multilayered Neural Network". Biological Cybernetics 20 (3–4): 121–136. doi:10.1007/BF00342633. PMID 1203338.
- Frank, Michael J. (2005). "Dynamic Dopamine Modulation in the Basal Ganglia: A Neurocomputational Account of Cognitive Deficits in Medicated and Non-medicated Parkinsonism". Journal of Cognitive Neuroscience 17 (1): 51–72. doi:10.1162/0898929052880093. PMID 15701239.
- Gardner, E.J., & Derrida, B. (1988). "Optimal storage properties of neural network models". Journal of Physics a 21: 271–284. doi:10.1088/0305-4470/21/1/031.
- Hadzibeganovic, Tarik & Cannas, Sergio A. (2009). "A Tsallis' statistics based neural network model for novel word learning". Physica A: Statistical Mechanics and its Applications 388 (5): 732–746. doi:10.1016/j.physa.2008.10.042.
- Krauth, W., & Mezard, M. (1989). "Storage capacity of memory with binary couplings". Journal de Physique 50 (20): 3057–3066. doi:10.1051/jphys:0198900500200305700.
- Maass, W., & Markram, H. (2002). "On the computational power of recurrent circuits of spiking neurons". Journal of Computer and System Sciences 69 (4): 593–616. doi:10.1016/j.jcss.2004.04.001. http://www.igi.tugraz.at/maass/publications.html.
- MacKay, David (2003). Information Theory, Inference, and Learning Algorithms. http://www.inference.phy.cam.ac.uk/mackay/itprnn/book.html.
- Mandic, D. & Chambers, J. (2001). Recurrent Neural Networks for Prediction: Architectures, Learning algorithms and Stability. Wiley. ISBN 0471495174.
- Minsky, M. & Papert, S. (1969). An Introduction to Computational Geometry. MIT Press. ISBN 0262630222.
- Muller, P. & Insua, D.R. (1995). "Issues in Bayesian Analysis of Neural Network Models". Neural Computation 10 (3): 571–592. PMID 9527841.
- Reilly, D.L., Cooper, L.N. & Elbaum, C. (1982). "A Neural Model for Category Learning". Biological Cybernetics 45: 35–41. doi:10.1007/BF00387211.
- Rosenblatt, F. (1962). Principles of Neurodynamics. Spartan Books.
- Sun, R. & Bookman,L. (eds.) (1994.). Computational Architectures Integrating Neural and Symbolic Processes.. Kluwer Academic Publishers, Needham, MA..
- Sutton, Richard S. & Barto, Andrew G. (1998). Reinforcement Learning : An introduction. http://www.cs.ualberta.ca/~sutton/book/the-book.html.
- Van den Bergh, F. Engelbrecht, AP. Cooperative Learning in Neural Networks using Particle Swarm Optimizers. CIRG 2000.
- Wilkes, A.L. & Wade, N.J. (1997). "Bain on Neural Networks". Brain and Cognition 33 (3): 295–305. doi:10.1006/brcg.1997.0869. PMID 9126397.
- Wasserman, P.D. (1989). Neural computing theory and practice. Van Nostrand Reinhold. ISBN 0442207433.
- Jeffrey T. Spooner, Manfredi Maggiore, Raul Ord onez, and Kevin M. Passino, Stable Adaptive Control and Estimation for Nonlinear Systems: Neural and Fuzzy Approximator Techniques, John Wiley and Sons, NY, 2002.
- Peter Dayan, L.F. Abbott. Theoretical Neuroscience. MIT Press. ISBN 0262041995.
- Wulfram Gerstner, Werner Kistler. Spiking Neuron Models:Single Neurons, Populations, Plasticity. Cambridge University Press. ISBN 0521890799.
- Steeb, W-H (2008). The Nonlinear Workbook: Chaos, Fractals, Neural Networks, Genetic Algorithms, Gene Expression Programming, Support Vector Machine, Wavelets, Hidden Markov Models, Fuzzy Logic with C++, Java and SymbolicC++ Programs: 4th edition. World Scientific Publishing. ISBN 981-281-852-9.
External links
- A Brief Introduction to Neural Networks (D. Kriesel) - Illustrated, bilingual manuscript about artificial neural networks; Topics so far: Perceptrons, Backpropagation, Radial Basis Functions, Recurrent Neural Networks, Self Organizing Maps, Hopfield Networks.
- LearnArtificialNeuralNetworks - Robot control and neural networks
- Review of Neural Networks in Materials Science
- Artificial Neural Networks Tutorial in three languages (Univ. Politécnica de Madrid)
- Introduction to Neural Networks and Knowledge Modeling
- Another introduction to ANN
- Next Generation of Neural Networks - Google Tech Talks
- Performance of Neural Networks
- Neural Networks and Information
- PMML Representation - Standard way to represent neural networks